Strengthening Data Sharing in Neuroscience: 5 takeaways from the IBI’s Data Sharing Symposium
As brain research initiatives around the world gather momentum, they are generating heaps of data—data that could unlock our understanding of the brain. But how can researchers within, across, and beyond those initiatives make use of all that new data? That question was the focus of a recent data sharing symposium organized by the International Brain Initiative’s Data Standards and Sharing Working Group at the INCF Neuroinformatics Assembly 2021.
The symposium highlighted the recent activities of the Data Standards & Sharing Working Group, which was launched in early 2020 to facilitate the sharing of data among global brain research initiatives, relevant scientific societies and other neuroscience researchers. Plus, in keynote presentations, two brain researchers at the forefront of data sharing in neuroscience described their data sharing efforts—and what has made those efforts both possible and successful.
The first was Kenneth Harris, a professor of quantitative neuroscience at University College London, who is part of the International Brain Laboratory, a collaborative neuroscience project focused on creating a brain-wide map of the circuits underlying decision-making, a single complex behavior in mice. IBL has built a virtual laboratory, or platform, to facilitate data sharing, within its team and with the neuroscience community globally. Kenneth described the IBL’s open-access data architecture pipeline and how it enables the sharing and analysis of massive amounts of neurophysiological and behavioral data among 22 independent labs.
The second presenter was Kristen Harris, a professor in the Department of Neuroscience at the University of Texas at Austin. At the symposium, she discussed her journey as an experimentalist who has generated a trove of neuroanatomical data, acquired over four decades studying the cell biology of learning and memory. Her neuroanatomical datasets, which have supported foundational discoveries in neuroscience, are now publicly available online to anyone in the research community who wants to view, analyze, visualize and build on them.
Stream the Data Sharing Symposium on INCF’s YouTube channel.
Here are five takeaways from the symposium:
Large-scale projects create unique (but solvable!) data challenges
Kenneth Harris underscored that team neuroscience, including in the form of the IBL, has a host of unique challenges. For starters, he said, large-scale data are messy. Secondly, data analysis software is critical to success and must be reliable. If the software only works 99 percent of the time, it is not going to be good enough. To address these challenges, the IBL team, which includes dedicated software engineers, has spent an enormous amount of time debugging software and ensuring it functions 99.9 percent of the time. Finally, he said unanticipated problems will arise, particularly with the custom experimental hardware commonly used in individual laboratories. As a result, large teams need to be nimble and adapt.
2. Fruitful data is the key to fruitful data sharing
Kirsten Harris has been collecting data on dendritic spines for four decades. Remarkably, some of the earliest data she collected, including original images and three-dimensional reconstructions of spines in brain tissue, are relevant to new research questions being asked today and are now available for public use. Kirsten acknowledged that she wasn’t thinking about data sharing when she was perfusing animals back in the early 1980s, yet her data are available and accessible today. How was she able to achieve this? The key is great data, she said at the symposium: “Great data keeps getting used. I expect there are experimentalists with a boatload of data that is ripe to be explored!”
Kirsten also outlined strategies for fruitful sharing:
Start local
Add collaborators to test data quality
Share via reliable sites
Keep data current—add reliable data to newly upgraded analysis pipelines
Return frequently to data and retest value in answering new questions
3. Data needs to be searchable
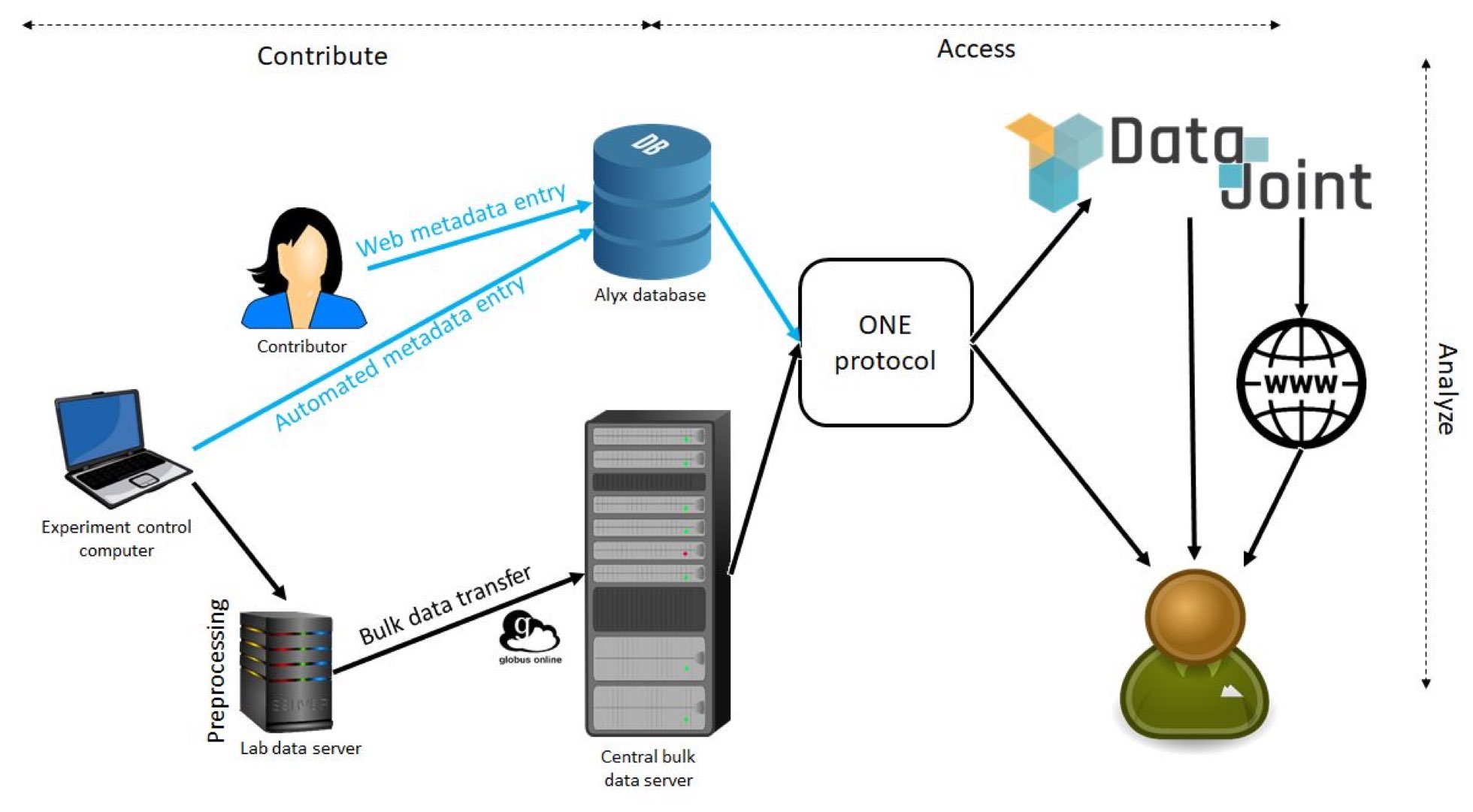
For the neuroscience community to reap the benefits of large-scale projects and the massive amounts of data they produce, the data must be gathered together in one place and made searchable. The IBL faced the challenge of integrating metadata with data from electrophysiology recordings, behavioral tasks, and much more. For it to be usable—both within the collaboration and outside of it—the researchers developed a pipeline to collect all the data in a single location, process it, evaluate it against defined quality control metrics, and make the data searchable and accessible.
4. Funding data-sharing infrastructure is critical
Kirsten Harris’s research on the cell biology of learning and memory has been supported by various funders, but a string of grants from the U.S. National Science Foundation's NeuroNex program enabled her to make her lab’s neuroanatomical data available to the wider neuroscience community. The NeuroNex funds have supported the development and maintenance of two web-based research platforms where the data, visualization and analysis tools, tutorials, and results are shared publicly with the goal of facilitating global collaboration. The two platforms are Synapse Web for three-dimensional ultrastructural brain data and 3dem.org for three-dimensional electron microscopy data. Kirsten stressed the need for dedicated funding to support data sharing: “There’s a need for substantial grant funding in everybody’s grants to have data scientists present to properly provide metadata and shared ontologies for the data we are collecting and sharing.”
5. Good data management is essential
Whether data sharing is built into the mission of a research team, such as the IBL, or happens organically, as it did for Kirsten Harris and her students, good data management is the foundation of data sharing. It starts with building a culture of documentation in the lab, according to symposium participants. “You have to prepare to share FAIR [findable, accessible, interoperable, reusable] and part of that is data management inside individual laboratories or groups of laboratories,” said Maryann Martone, co-chair of the IBI’s Data Standards & Sharing Working Group. Public data repositories can be helpful in establishing good data management practices and ensuring data is findable and accessible over the long term, the participants said. Trainees should receive the training and support they need to understand the benefits of data sharing and effectively manage their data from the outset of a research project.
Learn more about the International Brain Initiative’s Data Standards & Sharing Working Group
Figure: IBL data architecture. Data and metadata contributed from each lab are integrated into a relational database storing metadata, and a bulk file server storing binary files, via read-only connections. Users can access these data either directly through the Open Neurophysiology Environment (ONE) protocol, or via DataJoint, which also allows automatic pipelined analysis, and presents basic analyses on a website. (bioRxiv 827873; doi: https://doi.org/10.1101/827873)